
 @itaysk
@itaysk
 itaysk
itaysk
 itaysk
itaysk
A practical introduction to Azure Batch
Azure Batch, one of the possible ways to consume compute resources in Azure, is probably one of the least known ones, but is actually quite useful for scenarios of distributed parallel workloads. In this post I will introduce the basics of this service from a practical approach of just what needs to be done to get started.
Terminology and basic concepts
There are 3 fundamental concepts to Azure Batch that you have to know (there are more that you don’t):
Pool - A pool is a collection of VMs that can run your workload. Basically there are 2 types of pools: “Cloud Services Configuration” and “Virtual Machine Configuration”. Without going into details, just go with “Virtual Machine Configuration”.
Job - A job is an abstract definition of, well, a job. It’s no more than a unit of organization for your workload.
Task - A Task is the unit of work. Basically the command to be executed.
These are the three fundamental building blocks, and the relationship between them is that a job is associated to a pool, and tasks are associated to a job.
Additionally, there are special kind of tasks that help you with setting things up. We have those in the context of:
- pool - ‘pool start task’ prepares every node on the pool
- job - ‘job preparation task’ prepares for the job run.
Resource Files - those are files that that a task might need in order to operate. These will be downloaded into each node and made available for the task to use.
Basic workflow
- You prepare your code, and all it’s required resources.
- You put that in a shared storage accessible to batch. Usually Azure Storage Account.
- You create a pool of VMs, either on demand for your job, or you might have an existing pool to use.
- When the pool is provisioned it’s start task will run on each node.
- You create a job and associate it with the pool.
- When the pool is ready the job will be scheduled to run on it.
- You create tasks and associate them with a job.
- When the pool is ready, tasks will be queued to run on it’s nodes.
It’s important to remember that each of the job’s tasks will be scheduled to run on a node. I repeat - one task runs on one node (by deafult, you can configure otherwise).
Folder structure
Each batch node has a file system under /mnt/batch/tasks (I used Linux) which is the workspace for all of batch’s work. In this folder, you’ll find the following structure:
- shared - this is a folder shared between all the different parts of the Azure Batch framework.
- startup - task folder for pool startup task
- workitems
- $jobid
- subfolder
- jobpreparation - task folder for job preparation task
- $taskid - task folder for the tasks
- subfolder
- $jobid
Now, each one of these “task folder”s have the following stracture:
- certs
- stderr.txt - console error stream from the task
- stdout.txt - console output stream from the task
- wd - working directory for the task
- #task’s resource files will be here
Please note that this documentation of the folder hierarchy was by examining a live node and I provide it here for educational purpose. In your production code you should not rely on that, and instead use the environment variables that are build into every node and provide access to the important folders. See a complete list of available environment variables here: https://msdn.microsoft.com/library/azure/mt743623.aspx
Getting our hands dirty
There’s a .NET SDK, and a Python SDK. The UI very good and thorough, and there’s a community tool - Batch Explorer that is very useful as well. I used Python to create the resources, then used Batch Explorer for ad-hoc tasks or basic monitoring.
This is the Python code that creates the required resources in Batch:
The script is pretty simple to follow, and is organized in 3 sections: first we declare variables, second we create the batch objects and configure them (at this stage nothing is actually provisioned yet, we just create some objects in memory), and lastly we provision the resources. Only in the 3rd section does the client actually call the Azure Batch API.
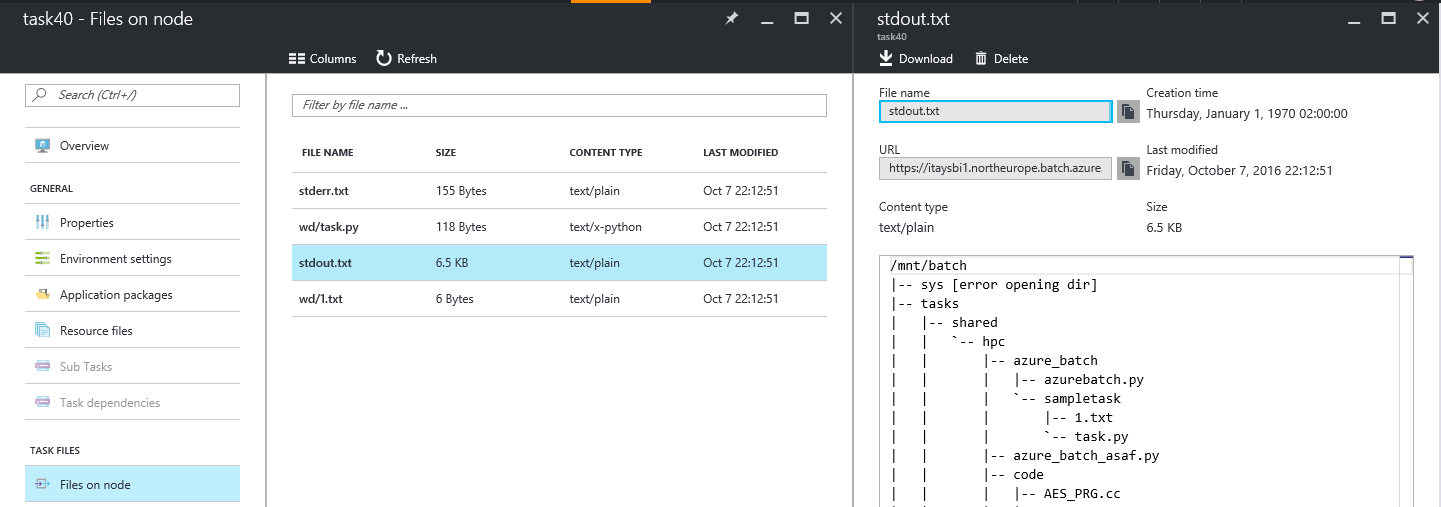
The portal offers excellent insight into the state and status of your tasks and jobs. One very handfull feature is the ability to pull the stdout, stderr from individual tasks without logging into VMs:
Caveats
Important things to know:
- A job cannot run for more than 7 days straight.
- You can control the scheduling mechanism.
- By default, tasks cannot communicate between each other but you can allow that explicitly.
- There is no VNET integration.
- By default, a node cannot run multiple tasks concurrently, but you can allow that.
- If you create many tasks a in single call, the SDK might generate a payload which is too large to be POSTed to Azure Batch’s API endpoint. If that happens you need to split your call into smaller batches.
Next steps
There is much more to know and learn about Azure Batch. There are configuration options we did not discuss, there are additional task types that might be useful, there are techniques for code deployment and log collection, the is inter-task communications and MPI, and container support and whatnot. This will not be covered here because this is the simple and practical tutorial to help you get started with Batch. For more information, please see Azure Batch’s documentation: https://azure.microsoft.com/en-us/documentation/learning-paths/batch/





